
Modèle de prédiction : guide d’intro à l’analyse quantitative | ParisPortifMethode
Le parieur qui souhaite dépasser l’intuition et l’analyse subjective se tourne naturellement vers la modélisation statistique. Construire son propre modèle de prédiction représente l’aboutissement d’une démarche analytique rigoureuse, transformant des données brutes en estimations de probabilité exploitables. Cette entreprise, intellectuellement stimulante mais techniquement exigeante, ouvre la voie à une approche véritablement systématique des paris sportifs. Comprendre les principes fondamentaux de la modélisation permet d’évaluer si cette voie correspond à vos compétences et à vos ambitions.
Pourquoi construire un modèle
Un modèle statistique offre plusieurs avantages sur l’analyse purement intuitive. Le premier est l’objectivité : le modèle produit les mêmes estimations face aux mêmes données, sans les biais cognitifs qui affectent le jugement humain. Le second est la systématicité : chaque match est analysé selon les mêmes critères, garantissant une cohérence impossible à maintenir manuellement sur des centaines d’événements. Le troisième est la scalabilité : un modèle peut évaluer des dizaines de matchs simultanément là où l’analyse manuelle atteint rapidement ses limites.
L’objectif d’un modèle de paris n’est pas de prédire qui va gagner avec certitude, objectif impossible, mais d’estimer des probabilités plus précises que celles implicites dans les cotes des bookmakers. Si votre modèle estime qu’une équipe a 55% de chances de gagner alors que la cote suggère 45%, vous avez identifié une opportunité de value bet. La qualité du modèle se mesure à sa capacité à battre le marché sur le long terme, pas à son taux de prédictions correctes.
La construction d’un modèle efficace demande des compétences en statistiques, en programmation et une connaissance approfondie du sport modélisé. Cette combinaison relativement rare explique pourquoi les modèles véritablement performants restent l’apanage d’une minorité de parieurs. Cependant, même un modèle imparfait peut apporter de la valeur en structurant l’analyse et en révélant des patterns invisibles à l’œil nu.
Les données : fondation du modèle
Tout modèle repose sur des données, et la qualité des données détermine en grande partie la qualité des prédictions. La collecte, le nettoyage et la structuration des données constituent souvent la partie la plus chronophage du processus de modélisation.
Les données de résultats historiques forment la base : scores, dates, équipes, compétitions. Ces données sont relativement accessibles via des bases de données publiques ou des API spécialisées. Leur fiabilité varie selon les sources, et une vérification croisée est recommandée.
Les données avancées enrichissent considérablement le modèle. Les expected goals (xG) dans le football, les statistiques de possession, les tirs cadrés, les duels gagnés offrent une image plus fine de la performance que le simple score. Ces données, plus difficiles à obtenir, peuvent faire la différence entre un modèle médiocre et un modèle performant.
Les données contextuelles capturent les facteurs situationnels : jours de repos entre les matchs, distance parcourue pour les déplacements, importance du match, conditions météorologiques. Ces éléments, souvent négligés, peuvent avoir un impact significatif sur les performances.

Les approches de modélisation
Plusieurs approches méthodologiques permettent de construire un modèle de prédiction sportive, chacune avec ses forces et ses faiblesses.
Les modèles de régression estiment une variable continue, comme le nombre de buts attendus, à partir de variables explicatives. Une régression de Poisson, particulièrement adaptée aux scores de football ou de hockey, modélise le nombre de buts de chaque équipe en fonction de leur force offensive et défensive. La distribution de Poisson permet ensuite de calculer les probabilités de chaque score exact et donc de chaque résultat.
Les modèles de classification prédisent directement la probabilité de chaque résultat possible. La régression logistique, les arbres de décision, les forêts aléatoires ou les réseaux de neurones peuvent être utilisés selon la complexité souhaitée et les données disponibles. Ces approches de machine learning excellent à détecter des patterns complexes mais risquent le surapprentissage si mal calibrées.
Les systèmes de rating, comme Elo ou Glicko, attribuent un score de force à chaque équipe mis à jour après chaque match. La différence de rating entre deux équipes traduit directement une probabilité de victoire. Ces systèmes, simples et robustes, constituent souvent un excellent point de départ.
Construire un modèle simple
Pour illustrer le processus, décrivons la construction d’un modèle Elo basique pour le football.
Le système Elo attribue initialement un rating identique à toutes les équipes, typiquement 1500 points. Après chaque match, les ratings sont ajustés en fonction du résultat et de la différence de rating préexistante. Une victoire inattendue contre une équipe mieux classée génère un gain de points important ; une victoire attendue contre une équipe faible génère un gain modeste.
La formule de mise à jour s’écrit : nouveau_rating = ancien_rating + K × (résultat_réel – résultat_attendu). Le facteur K contrôle la vitesse d’adaptation du modèle. Le résultat attendu se calcule à partir de la différence de rating selon une formule logistique. Le résultat réel vaut 1 pour une victoire, 0.5 pour un nul, 0 pour une défaite.
Une fois les ratings établis sur l’historique, la prédiction pour un nouveau match utilise la différence de rating pour estimer les probabilités. Cette estimation, comparée aux cotes du marché, révèle les potentiels value bets. Le modèle Elo basique est simpliste mais constitue un point de départ fonctionnel que vous pouvez ensuite enrichir.
Valider et améliorer son modèle
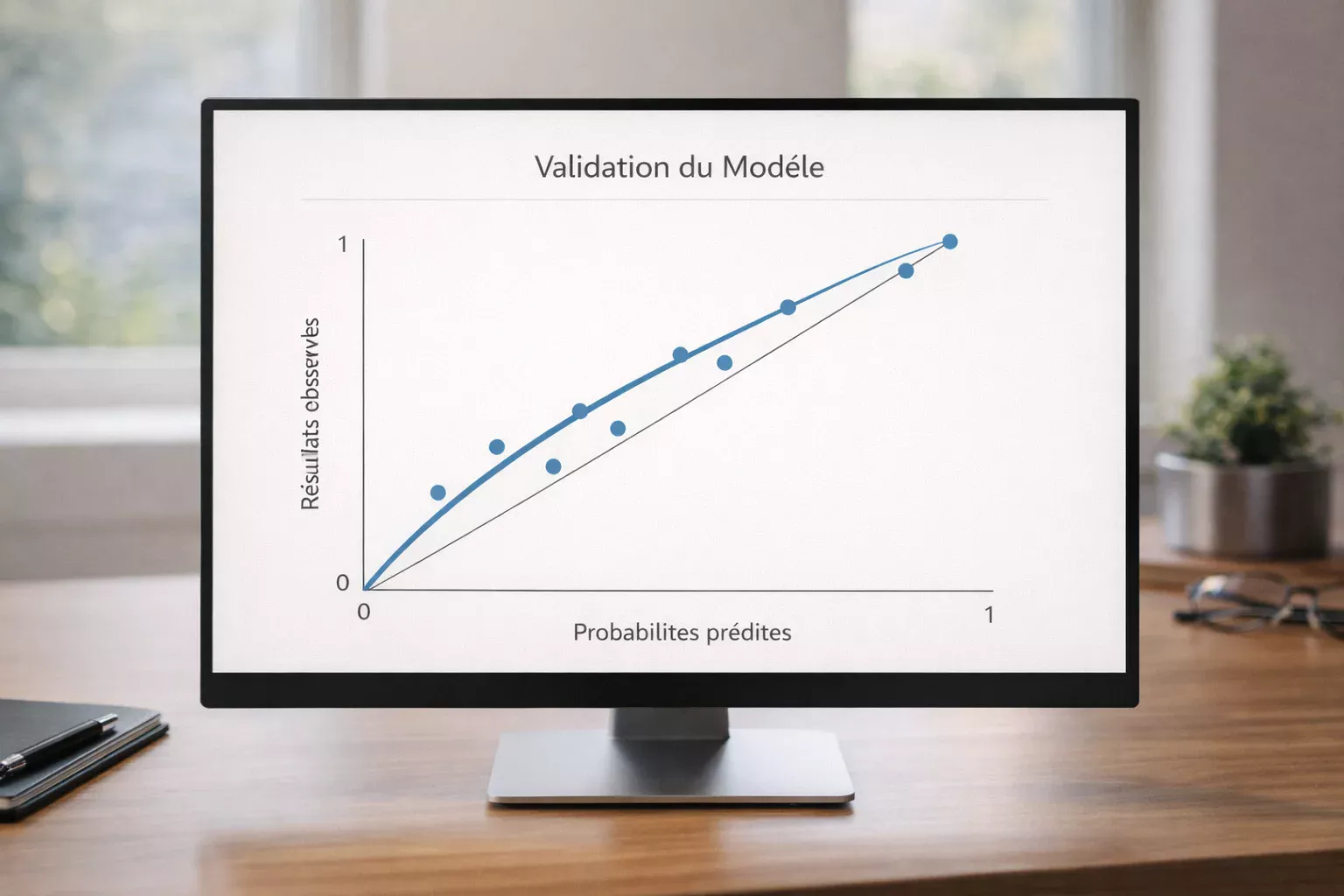
Un modèle n’a de valeur que s’il est validé sur des données qu’il n’a pas vues pendant sa construction. La validation rigoureuse distingue les modèles véritablement prédictifs de ceux qui ne font que mémoriser le passé.
La validation out-of-sample divise les données en ensemble d’entraînement et ensemble de test. Le modèle est construit uniquement sur l’ensemble d’entraînement puis évalué sur l’ensemble de test. Cette séparation simule les conditions réelles où le modèle doit prédire des matchs futurs.
Les métriques de validation mesurent la qualité des prédictions. Le Brier score évalue la calibration des probabilités : des prédictions à 60% devraient se réaliser environ 60% du temps. Le log loss pénalise les prédictions confiantes mais incorrectes. Le yield simulé sur les paris historiques donne une indication directe de la rentabilité potentielle.
L’amélioration itérative teste différentes modifications du modèle. Ajouter une variable, changer un paramètre, essayer un algorithme différent sont autant d’expériences dont l’impact est mesuré sur l’ensemble de validation. Cette démarche scientifique, bien que fastidieuse, est la seule voie vers un modèle véritablement performant.
Les pièges de la modélisation
La construction de modèles comporte des pièges dans lesquels tombent régulièrement les débutants.
Le surapprentissage, ou overfitting, survient quand le modèle capture le bruit plutôt que le signal dans les données d’entraînement. Un modèle trop complexe peut avoir des performances spectaculaires sur le passé mais désastreuses sur les nouvelles données. La régularisation et la validation croisée protègent contre ce piège.
Le data snooping consiste à tester de nombreuses variantes du modèle jusqu’à en trouver une qui fonctionne bien sur les données historiques. Cette optimisation excessive crée l’illusion de performance qui s’évaporera face aux données futures. Définir les règles du modèle avant de regarder les résultats évite ce biais.
L’ignorance des changements structurels néglige le fait que les conditions du sport évoluent. Les règles changent, les styles de jeu évoluent, les équipes se transforment. Un modèle calibré sur des données anciennes peut devenir obsolète si les patterns historiques ne s’appliquent plus.
Intégrer le modèle dans sa pratique
Un modèle fonctionnel doit s’intégrer dans un processus de pari cohérent pour générer de la valeur.
L’automatisation de la collecte de données et de la génération de prédictions libère du temps pour l’analyse et la décision. Un script qui récupère les matchs du jour, calcule les probabilités et identifie les écarts avec les cotes du marché transforme le modèle en outil opérationnel.
Le dimensionnement des mises utilise les probabilités du modèle dans un cadre de gestion de bankroll comme le critère de Kelly. L’avantage estimé par le modèle détermine la taille de la mise, liant directement la confiance statistique à l’exposition financière.
Le suivi des performances mesure en continu si le modèle tient ses promesses. Un tracking rigoureux du yield réel comparé au yield attendu révèle les dérives et signale quand une recalibration est nécessaire.
Les limites de l’approche quantitative
La modélisation statistique, malgré ses avantages, ne constitue pas une solution miracle.
Les données ne capturent pas tout. La motivation, la dynamique de vestiaire, les instructions tactiques spécifiques, les conditions psychologiques échappent largement à la quantification. Ces facteurs qualitatifs peuvent faire la différence dans certains matchs.
Le marché intègre aussi l’information. Les bookmakers et les parieurs sophistiqués utilisent également des modèles. Battre le marché exige non pas un bon modèle mais un meilleur modèle que le consensus, ce qui est considérablement plus difficile.
La variance reste irréductible. Même un modèle parfait ne gagnerait pas tous ses paris. Les séries perdantes, statistiquement normales, peuvent déstabiliser le modélisateur qui doute alors de son approche. La confiance dans la méthode doit résister aux fluctuations de résultats.
Conclusion : une voie exigeante mais gratifiante
Construire son propre modèle de prédiction représente un investissement considérable en temps et en compétences. Les obstacles techniques sont réels, les pièges méthodologiques nombreux, les résultats incertains. Beaucoup commencent cette aventure sans jamais la mener à terme.
Pour ceux qui persévèrent, la modélisation offre une satisfaction intellectuelle profonde et potentiellement un avantage compétitif durable. Comprendre véritablement ce qui détermine les résultats sportifs, transformer cette compréhension en prédictions quantifiées, voir ces prédictions se traduire en profits constitue un accomplissement rare dans le monde des paris.
Le chemin vers un modèle performant est long et semé d’échecs. Commencez simple, validez rigoureusement, améliorez progressivement. Cette approche patiente et méthodique offre la meilleure chance de rejoindre la minorité de parieurs qui ont transformé l’analyse quantitative en source de revenus.